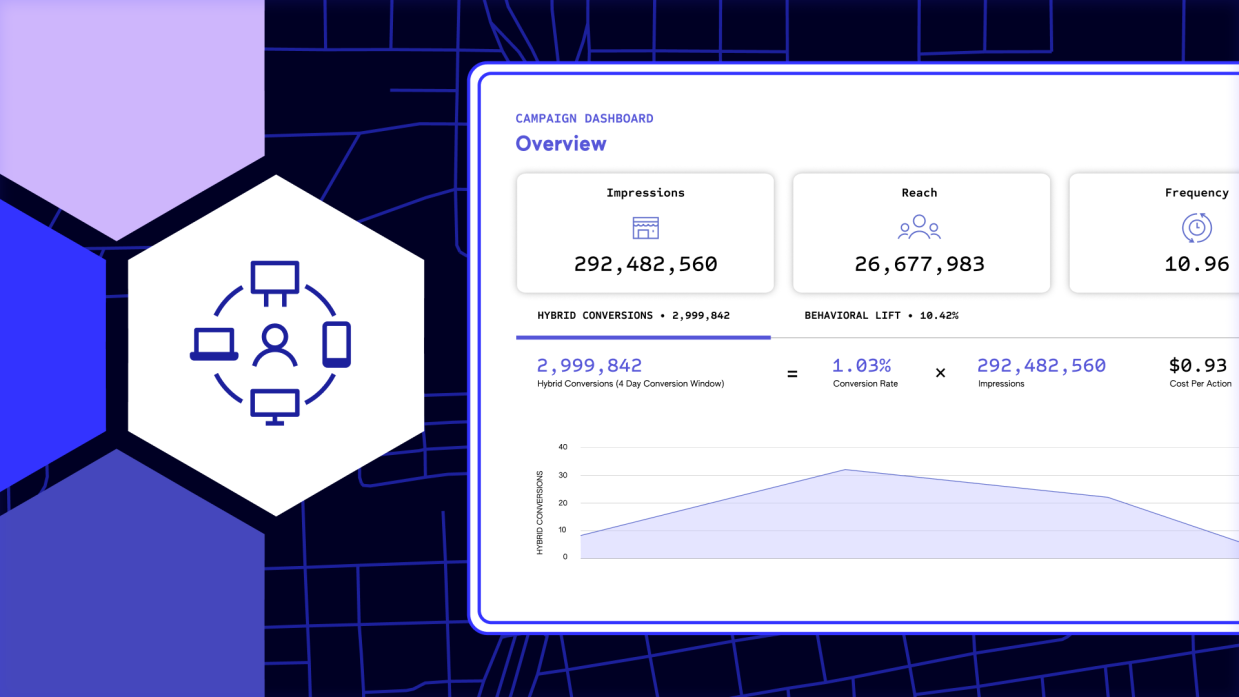
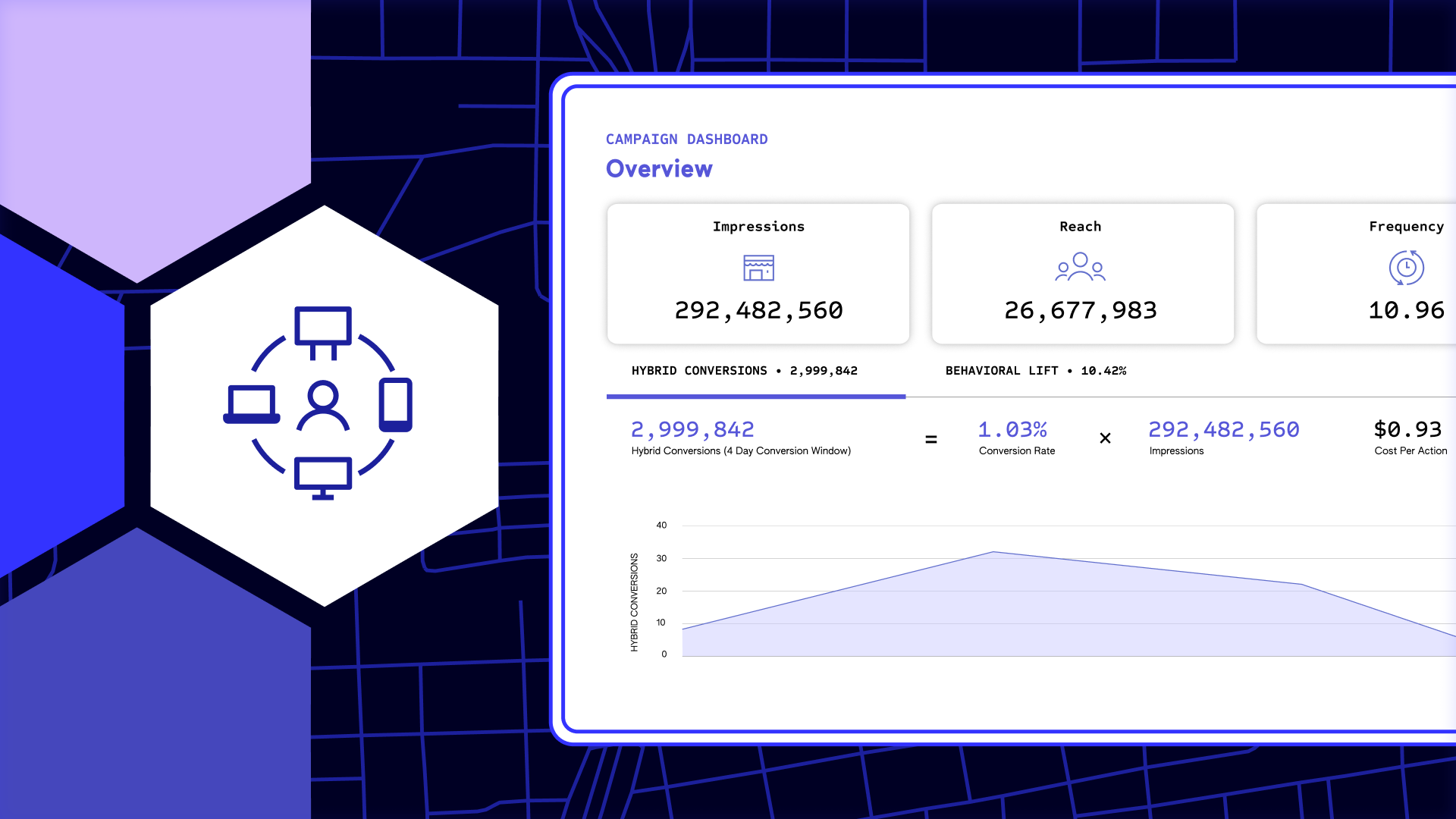
The Importance of Multi-Touch Attribution
April 18, 2024If businesses wish to increase success with digital marketing, they must consider multi-touch attribution (MTA). MTA is a more precise…

FSQ Faces – Alicia Donovan Brainerd, Director, Engineering
April 17, 2024We are excited to welcome Alicia Donovan Brainerd to Foursquare as a Director of Engineering! Together, we’ll learn more about…
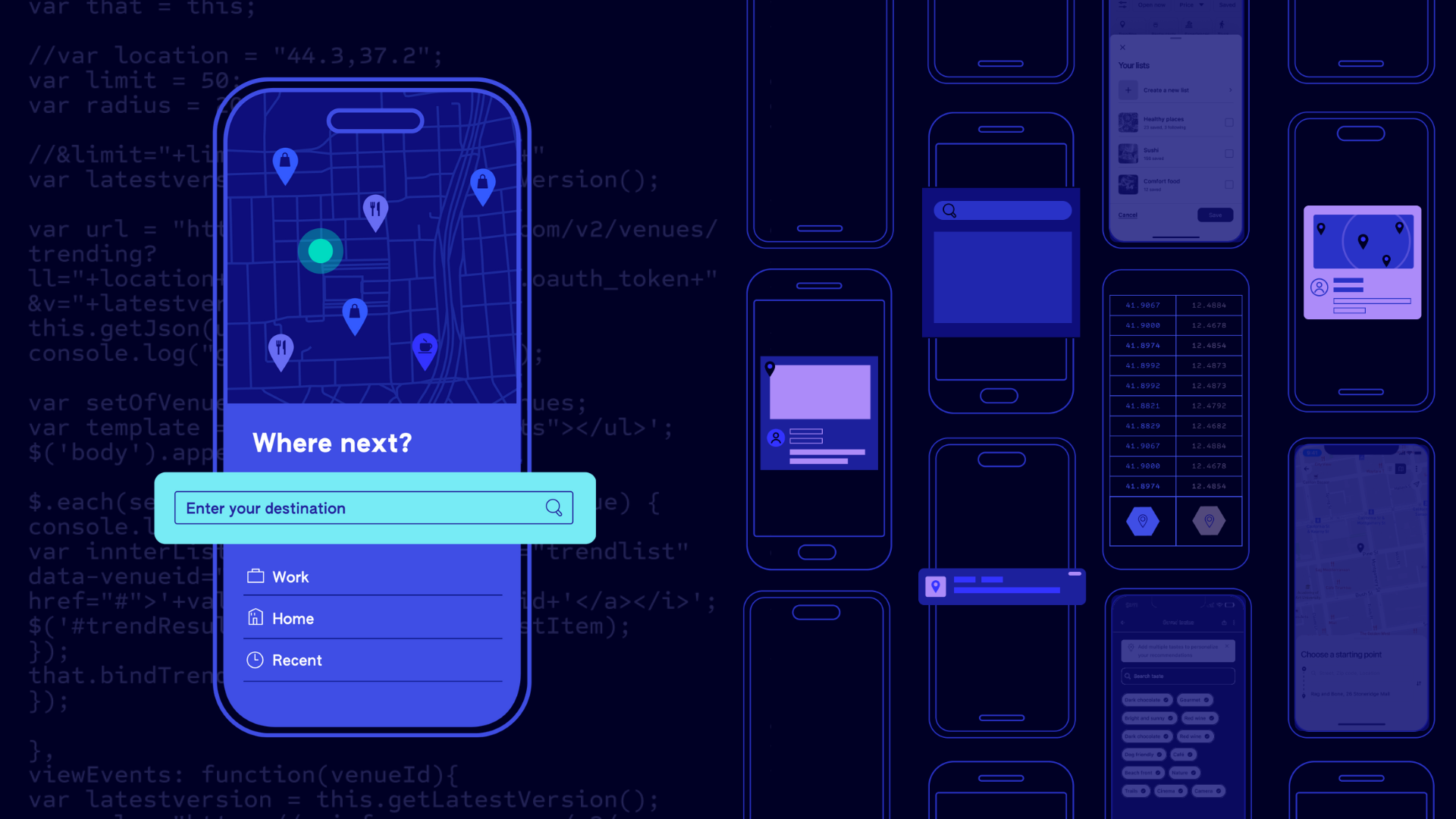
Using Foursquare’s Places API to Enhance User Experience
April 11, 2024The digital age has changed the way we find information. Instead of flipping through the Yellow Pages, users turn to…

Phones, Lambdas and the Joy of Snap-to-Place Technology
April 10, 2024Before diving into lambdas, trees, and joy functions, we’ll start this overview of Foursquare’s Snap-to-Place technology with background on unique…

Building More Contextualized App Experiences with Location-based SDKs
March 28, 2024Location is a key consideration for app developers who want to provide a better experience for users. Location-based SDKs are…

How In-Person Meetups Catalyze Innovation
March 26, 2024In the Flatiron District of New York City, Foursquare’s headquarters serves as a major hub for hosting regular meetups for…